 ���ں�
���ں���С�����ɼƻ� �Ź־���СѾͷ���ɱ��
2019-11-22 09:58:15
- +1 ������
���켫���ҵ�Ƶ������2014�꣬��С����������������������˹����������������ά�ȷ�չ��С�������ϼ�ǿ��������EQ������ijɳ�������Ŀǰ��С����������7���ݽ�3��Σ������ڻ������˹����ܽ����������й١�ӵ�и��й۵ĵ��ߴ�С�����Ի����������ʵ��������ʽ�Ի���������
���˵С����������Ϊҫ�۵ijɾͣ�������5��ʱ�����չ�ֵ�����������Խ����ż��ij���ʵ�����Լ�����7���������������״ξٰ�ĸ��˻滭չ��
��С���ɳ��ı����벻�����ġ����ɡ����˴Σ��켫��������3λ��(����)����������Ժ��ѧ�ҽ��жԻ���������С��������Щ��Ϊ��֪�ļ������¡�
���������걸�ĶԻ�������
��NLP��������С���������ǣ������ܴ�����Ի���ѧϰ����ȥ˵������Ҫ�봹ֱ����������Ļ����˽�����Ϣ����������������������ACL����������һ�γ��ԣ�����������ģ����ѵ�������л�Ϊʦ����ÿ�ε��������ܽ�֪ʶ���������һ��ģ�ͣ�ͬʱ���ܴ�����һ��ģ���нӴ���֪ʶ���Ӷ�ʵ�ֻ���ѧϰ��
����С����ϯNLP��ѧ���������ܳƣ�����һ��ʼ������ģ�ͣ�ͨ���������е�����Ի���ʵ���˻��������������з�������ģ�ͣ�С��ʵ�����ܹ�����ȥ�ϳɻظ����ٵ��ֽ�Ĺ���ģ�ͣ���С��ӵ���˰ѿ������Ի����̵���������

��С����ϯNLP��ѧ������
��Щ�����ı������ɺ��ĵĶԻ�������йᴩ�������ڼ�LSTMģ�͵����µ�BERTԤѵ����ģ�ͣ�ģ�͵��������˼����Ծ��ģ�͵��ݽ����̣�Ҳӡ֤��С���ӵ��ֵ����֡���dz���ƥ�䵽���α�ʾ�ijɳ�֮·��

����ҵ�磬�ܶ�����Ϊ���ѧϰ�ı��ʾ��DZ�ʾѧϰ�����б�ʾָ����ͨ��ģ�Ͳ��������ú��ַ�ʽ����ʽ����ʾģ�͵�����۲���������ʾѧϰ����ָ�Թ۲���������Ч��ʾ��˵ͨ��������������ô����ʾ�û������Լ��ظ���ѡ��
�����������ǣ�������ͻظ���ѡ��ÿһ�����϶����н������õ�һ����ֵĽ��������ٰѽ�������Ϣ�����������ͨ���������ȡ������Ҳ���ǽ��ⲿ֪ʶ���뵽ƥ����������֪ʶ���桢������桢���������б�ʾ�����ڶ��������Ͻ��н��������հѶ��������Ͻ��н�������Ϣ������ںϳ��������ͻظ���ѡ��ƥ�䡣
������ģ�ͷ��棬Ϊ�˴�����ĶԻ���ѧϰ˵���ļ��ɣ��Ե�5��С����ʼ�����㽨����һ��1:1������ģ�͡�����������ģ�ͣ���С����һ��ֻ�ܽ��е�һģ̬�ظ���AI����Խ���˽��ж���������Ϣ�ظ�(���������Ӿ�������)�ĶԻ������ˡ�
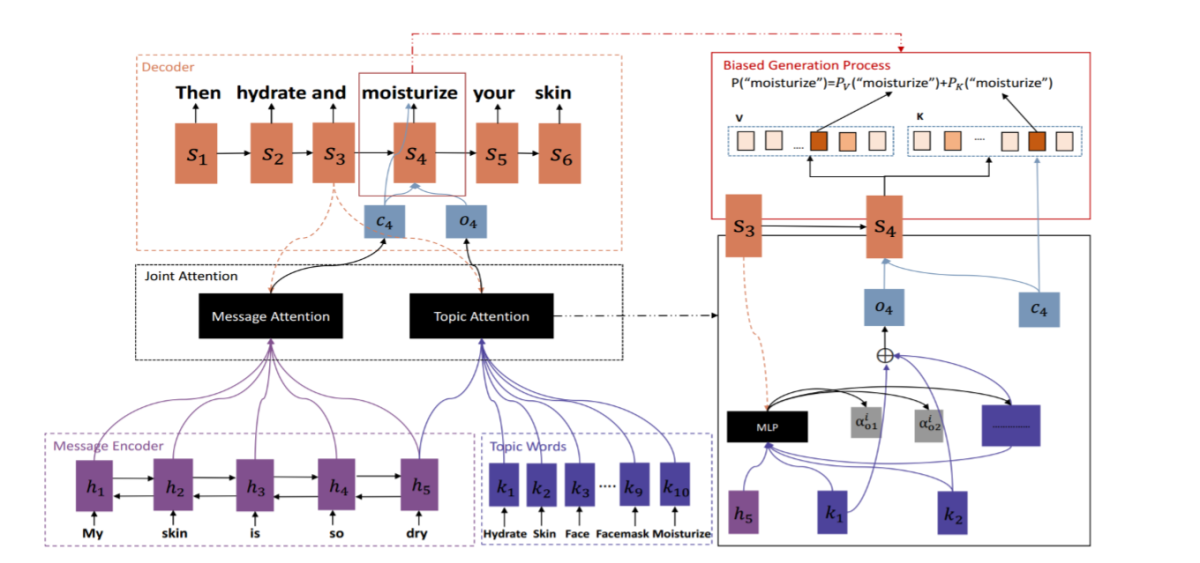
�ٸ����������������ֽ�������С��˵��������Щ��Ѫ˿����С�������С���Ҳ�����м�������ظ��������У���ͨ���ⲿ���ලѵ������ģ�ͣ�����һЩ��������(�����м�����)���������ģ��ͨ��һ������ע�������ƣ�ȥ���л������ϵ���ѡ�����ڽ���Ĺ����е�������һ����������ɸ��ʡ�
��Ȼ��������������ģ���⣬С���ɳ�����һλ����ʦ������ģ���ò��ᣬ�Ե�6������ģ�ͳ��ֺ���������С��Ӧ��˵ʲô�Լ�����ȥ˵�������ƣ������ģ����С����ԭ������������ֱ�Ӳ����ظ���ģʽ����Ϊ�˴������ĵ����ߣ��پ��ظ���ģʽ��������������Ծ�������ν�IJ��ԣ�������Կ�����һЩС����Ҫ�������ͼ��������һ���Է��ڱ���ʲô����
������ͼ��ʵ����ȷ������Ҫ����AIͨ����ģ̬��֪ʶ������һ�𣬽������������գ������γ�һ���л����������С���ܹ����߸������������жԻ���
����Ҫ��˵ ��Ҫ�ᳪ
���˻�˵�⣬������һ�����ɼƻ�����Ҫ����С�����ڳ��衣��������Ի������ֽ�Ȼ��ͬ�Ŀ��⣬��Ե���սҲ���ྶͥ��
����˵����ÿ����ѧ����ͨ�����ף���������ÿ���˳��趼���ܵ�ȴ���ѡ��������ѧϰ��Ҫ���������ݣ��ڶԻ�ѵ���У��������Ŵ����ĵ���֪ʶͼ�ס�ͼƬ����Ƶ���Լ��������������Ȼ���ƣ�������������Ȼû��̫�����������Դ��������������������ճ��Ͱ壬���Ҫ������н�����������������ֶ��������������ߣ����軹Ҫ���ٷ��������ġ����ɵȶ�Ԫ������ս��
����ǰ����ͳ�ϳɵķ����ǣ�����Ԫ����ƴ�ӣ�¼�Ʋ�ͬ���ȡ���ͬ���ߵĶ����������Ӷ�����һ����Ԫ�⡣�ںϳ�ʱ���ӵ�Ԫ����ѡһ�����Ҫ��ĵ�Ԫ����������ʱ�������ߴﵽԤ��Ч�����ٽ���Щ��Ԫ�����������е�Ԫƴ�ӣ��õ��������Ƶ��
��Ȼ��������Ƚϼ�Ҳ�ܵõ�������ʣ�����������������ڵ�Ԫ�ɼ����ڡ������ַ������ɳ��ĸ������Ƚ���ӲһЩ���ַ�֮���������������ڡ��ġ����ǡ���������ˣ���ѡ������һ����·���������ϳɡ�

����С����ϯ������ѧ���」���ܳƣ��������ϳɵķ�����������ڣ�ǰ���ǽ�����Ԫ�⣬�������ǽ�����¼����������ȡ����ѧ����(ʱ�������ߵ�)���н�ģ���ϳ�ʱ������Ҫ������ģ����Ԥ�⣬��ͨ�������ѧ�������������ع���Ƶ���Ρ���

��С����ϯ������ѧ���」
����������ŽΣ������ģ�;��ǽ������е�����Ҫ�ؽ��вɼ����ֱ�����ײ������������С����߹켣���н�ģ�����������ڣ�ͬһ�������ڸ�����������кܴ���죬�����ͬ���ķ�ʽ��������Ȼ�ǻ��������ġ�
Ϊ����С�����ף����뵽����һ�֡����ɡ���ʽ�����ǽ���������ߵ�Ԥ������Ϊ���룬�������ײ���Ԥ������ڴ˻����ϣ����в���֮������Ե���������һ��ģ��ͬʱԤ���������������Ӷ������ݳ�ʱ����Ȼ�Ⱥ������ȡ�

����!������С��˵�ıȳ��Ļ���
�������ǽ�����С������Ȼ���Դ����Լ��質ʵ��������Զ�������ڴˡ����꣬������С��ʵ�ֵ��ǡ���˵��Ҫ�ȳ��Ļ���!
��ʵ�����뿴���ģ���С���ܹ�ʹ�ñ�������ĸ����ַ����Ӷ��öԻ���ʽ��Ϊ��ӱ��������˵�������DZ��壬��ѧ�����壬����ȥ�Ǻ�����ص�����������併ά��һ������������������Χ����Ͷ�䣬�ҵ��ν����ߵĹؼ��ʽ��д������ó��������Ǹ��ӵģ�����ѧһ�����Ķ���
�����п�����С���Ա�������������⡣�����ǰѱ�����Ϊ���Ϲؼ��֣�����������������������û�ǰʮ��������ҳ�����(�����ṹ������ʶ��������)��������NLP�������ҳ�����ν�ṹ���������Ե�ƥ�䣬ͨ�������������ҵ�[����]��[��ѧ]��[����]֮����ڵ�һ�ֹ�����
��С����ϯ��ѧ�������ʾ�����������ǵ������������һ�����������ԣ�����֮��û���ر���ȥ�ᵽ�������ı������������һ�ֹ�������ӱ�ĸо�����

��С����ϯ��ѧ�����
������������һֱ��ͼ��С��ӵ��ģ�������������������С����EQ�ܲ������ࡣ������7�����ݽ��У����Ҳ��֤��С����һ���¶���С����ɱ䵽һ���Ź־���СѾͷ�����̡�
��С���ijɳ������������ֽ��С������ʱ���������Լ�����������Ӱ������Χ�ġ������ǡ�(�������ס�С�ס���Ѷ����Ϊ�ĺ���)������һ�죬С������ְ����������������������ҵ��·�Ͼ����Լ�������










��ΰ
������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼





























